Why determinism is the most underrated principle in software engineering — and how to apply it at every level
The Boring Reason Systems Fail
Most software systems don’t fail because of microservices. They don’t fail because of monoliths. They don’t fail because of agile. They fail for a much more boring reason: they’re unpredictable.
If you make a change and can’t reliably determine the impact of that change, you can’t safely evolve your system. And if you can’t evolve your system, it’s already a legacy system — regardless of when it was written.
This is a problem of determinism: the property that the same input always produces the same output. It sounds obvious. It’s anything but.
Determinism is the bridge between “it works on my machine” and “it works every time, everywhere.” And if you care about continuous delivery, about evolutionary architecture, about building systems that improve instead of decay — you should care deeply about determinism.
The Chain: Why Determinism Enables Everything Else
There’s a logical chain that connects determinism to your ability to evolve a system:

You can’t evolve what you can’t measure. You can’t measure what you can’t repeat. And you can’t repeat something that isn’t deterministic.
If your tests are flaky, if your builds sometimes fail “for reasons,” if concurrency randomly breaks things — then your delivery pipeline stops being a real learning system. It becomes release theater: going through the motions without actually validating anything.
Determinism is the prerequisite for trust. Without it, your tests lie to you. Your pipeline lies to you. Your architecture rots quietly in the background.
With it, you can run thousands of experiments per day. You can detect unintended consequences. You can move fast without gambling. That’s an evolutionary capability.
The Four Enemies of Determinism
Non-determinism doesn’t come from one place. It sneaks in through at least four distinct channels, each requiring a different fix.
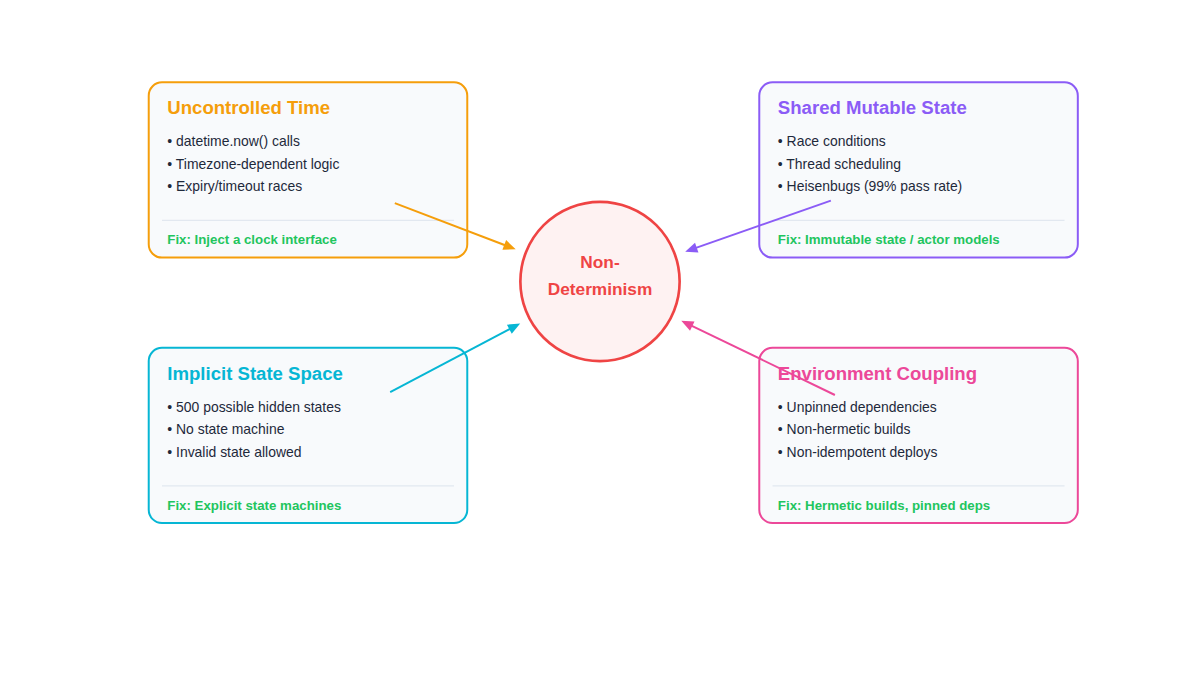
Let’s examine each one.
Enemy 1: Uncontrolled Time
If your code calls datetime.now() directly, you’ve just injected non-determinism into your system. The same input tomorrow produces a different output. That’s not testable. That’s not reproducible. That’s not evolutionary.
This is one of the most common sources of non-determinism, and one of the easiest to fix.

The Fix: Pass Time as Data
Instead of reaching for the system clock inside your business logic, inject a clock interface. Treat “now” as an input parameter, not a global variable.
Something magical happens when you do this:
- Freeze time — test what happens at exactly midnight on December 31st
- Fast-forward — simulate a 30-day expiry window in milliseconds
- Replay production bugs — feed in the exact timestamp from the production log
- Test DST transitions — create a clock that jumps forward/backward at will
You’ve turned the universe into a parameter. That’s a powerful tool.
Real-World Example
In our codebase, our OXI outage detection system runs differently depending on business hours (6 AM–11 PM in a specific timezone). Without clock injection, testing this logic requires either running tests at specific times of day or hacking the system clock. With clock injection, we test every hour of every timezone in milliseconds.
Enemy 2: Shared Mutable State
Concurrency is where determinism goes to die.
If thread scheduling decides the order of execution, your architecture is now probabilistic. It’s subject to random race conditions and Heisenbugs — bugs that disappear when you try to observe them. You’ll be familiar with the phrase “well, it works 99% of the time.” That’s not engineering. That’s roulette.
The Fix: Remove the Mutation
There are effective ways to handle concurrency without sacrificing determinism:
- Actor models — each actor processes messages sequentially, no shared state
- Single-threaded event loops — one thread, deterministic ordering
- Immutable state — when state doesn’t mutate unpredictably, order stops mattering quite so much
- Deterministic merge strategies — when you must combine results, make the merge itself deterministic
The key insight: when execution is structured as input → decision → event, you regain control. Each step is a pure transformation that can be tested independently.
What This Looks Like at Scale
Dave Farley describes a system at LMAX that processed global financial trades where each service was completely deterministic. Given the same starting state and the same sequence of events, they got exactly the same result every time. This isn’t academic purity — it’s how you build systems where evolutionary change is safe, because you can always verify the impact.
The Central Pattern: Deterministic Core + Imperative Shell
If you take one idea away from this entire article, take this one: separate the code that decides from the code that acts.
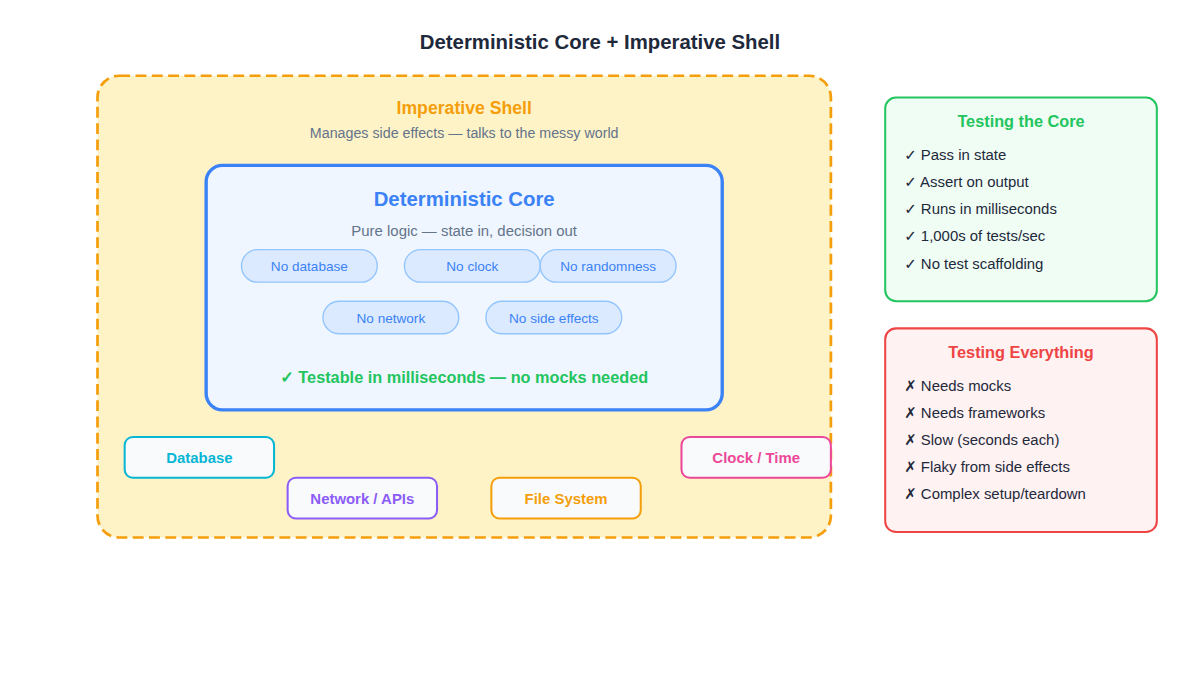
The Deterministic Core
This is where your business logic lives. Pure functions that take state in and produce decisions out. No database interactions. No clock. No randomness. No network. No side effects.
Because the core is pure:
- You don’t need mocks
- You don’t need frameworks
- You don’t need complex test scaffolding
- You pass in state, you assert on output
- You can run thousands of tests in milliseconds
Those are your fitness functions at scale. And now your architecture can evolve safely, one bit at a time.
The Imperative Shell
This is where you deal with the messy world: talk to the database, talk to the network, read the clock, execute side effects. The shell is thin, mechanical, and boring by design. It converts the outside world into inputs for the core, and converts the core’s decisions into actions.
Why This Works
This pattern isn’t new. It’s separation of concerns. It’s hexagonal architecture. It’s ports and adapters. But framing it through the lens of determinism makes the benefit crystal clear: the core is where your tests give you confidence, and the shell is where you manage the chaos.
When the core is pure, testing is trivially fast. When the shell is thin, there’s less surface area for non-determinism to hide in. The result is a system you can change with confidence.
Enemy 3: Uncontrolled State Space
Non-determinism isn’t only about threads or clocks. It’s about uncontrolled state space.
If your system has 500 possible implicit states and you don’t know which one you’re in at any given moment, you don’t have architecture — you have entropy.
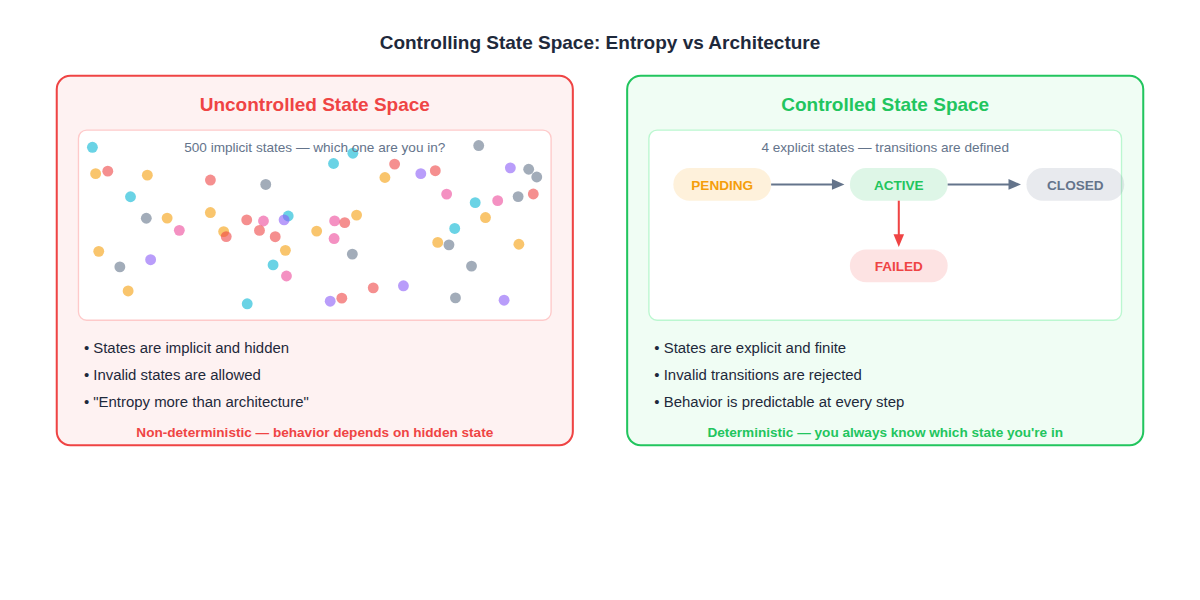
The Fix: Make State Explicit
Design narrower scopes. Use explicit state machines. Make boundaries between components serving different purposes clear. Design components to reject invalid states.
The narrower the scope, the more control you have over state. The more control you have over state, the more deterministic the system becomes. And the more deterministic it becomes, the more confidently you can change it.
What Explicit State Looks Like
Instead of a boolean isActive and a nullable completedAt and a string status that might be any of 12 values — use a state machine with 4 defined states and 5 valid transitions. Now:
- You always know which state you’re in
- Invalid transitions are rejected at compile time or runtime
- Every state transition is testable
- The system’s behavior is predictable at every step
This is evolutionary architecture in practice: not a grand upfront design, but structural choices that keep the system changeable.
Enemy 4: Environment Coupling
Determinism doesn’t stop at code. It extends to your entire software supply chain.
Hermetic Builds
If the same source code produces different artifacts depending on when or where you build it, your build is non-deterministic. Hermetic builds — builds that are fully self-contained and reproducible — ensure that the same source always produces the same binary.
Pinned Dependencies
If your build pulls “latest” versions of dependencies, you’ve introduced non-determinism at the supply chain level. A library update on Tuesday could break your Friday build, and you’d have no idea what changed. Pin your dependencies. Lock your versions.
Idempotent Deployments
If applying your deployment twice changes the result, your infrastructure is non-deterministic and your production environment is, as Dave Farley puts it, “a mystery wrapped in an enigma.”
Idempotent deployments mean: run it once, run it ten times — same result. Infrastructure as code. Declarative configuration. No manual steps that someone might forget or do differently.
The Payoff: Speed of Learning
Most organizations optimize for features. But the best organizations optimize for speed of learning.
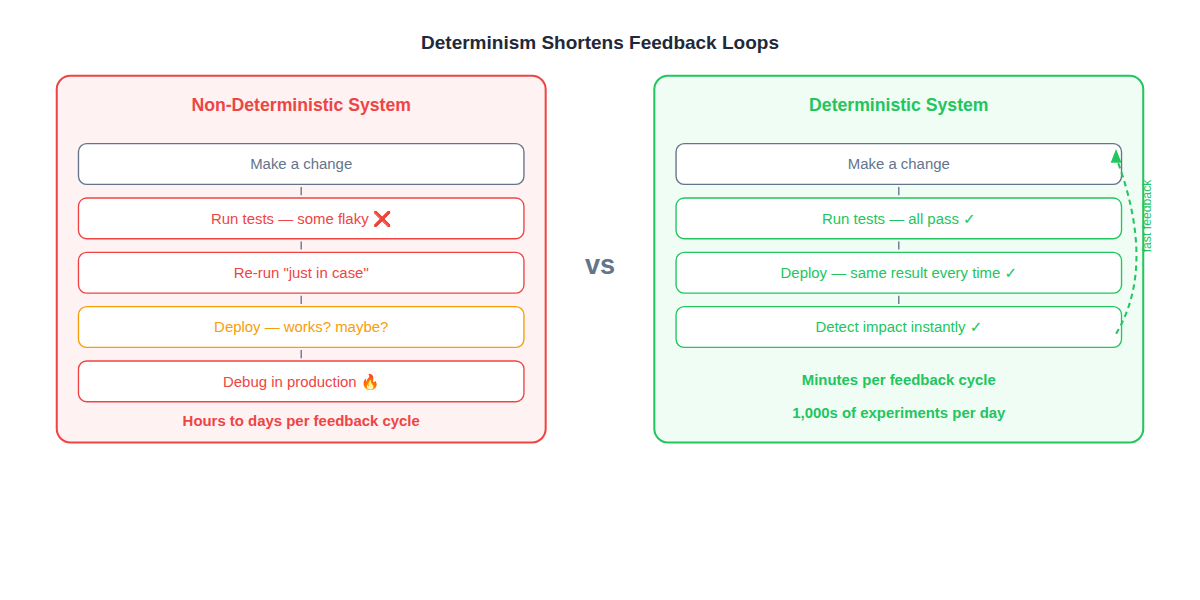
Deterministic systems deliver three compounding benefits:
1. Shorter Feedback Loops
When tests are deterministic, you know immediately whether a change broke something. No re-runs “just in case.” No “it was probably a flake.” The feedback is instant and trustworthy.
2. Reduced Cognitive Load
When the system is predictable, developers don’t need to hold the entire state space in their heads. They can reason locally about the component they’re changing, because the boundaries are clear and the behavior is consistent.
3. Reproducible Debugging
When a bug happens in production, you can reproduce it locally by feeding in the same inputs. No more “I can’t reproduce it” — because the system is deterministic, the same inputs always produce the same failure.
These benefits compound. Shorter loops mean more experiments. More experiments mean faster learning. Faster learning means better software. This is why continuous delivery works — not because of pipelines, but because of determinism. The pipeline is just the amplifier that helps you see how close you are to it.
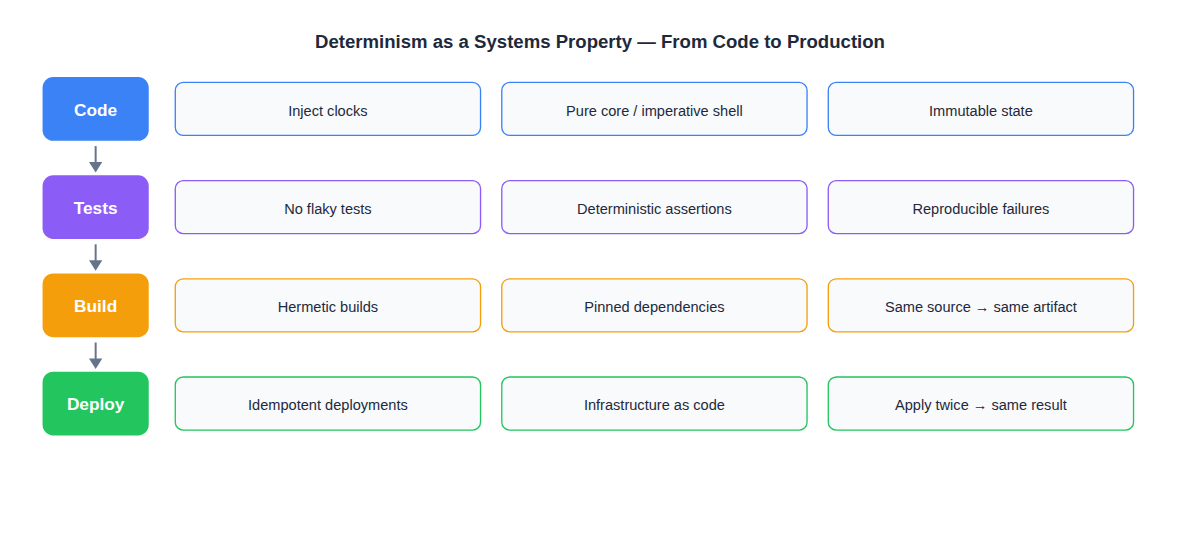
Practical Checklist
Here’s how to increase determinism in your system, starting today:
Code Level
- Inject clocks instead of calling
now()directly - Separate pure business logic from side-effect code (core + shell)
- Use immutable data structures by default
- Avoid shared mutable state between threads
- Make random number generators injectable/seedable
Testing Level
- Eliminate flaky tests — each one is a determinism leak
- Use deterministic assertions (exact values, not “not null”)
- Make test data factories produce reproducible output
- Run tests in isolation — no shared database state between tests
- Treat a flaky test as a P1 bug, not an annoyance
Build Level
- Pin all dependency versions (lock files, exact versions)
- Use hermetic builds (same source = same artifact, regardless of when/where)
- Cache build outputs by content hash, not by timestamp
- Verify builds are reproducible by building twice and comparing
Deployment Level
- Make deployments idempotent (apply twice = same result)
- Use infrastructure as code with version-controlled configuration
- Eliminate manual deployment steps
- Test rollbacks — they should produce a known prior state
The Key Insight
Determinism isn’t a coding trick. It’s a systems property. It’s not about purity for its own sake — it’s about building systems where change is safe, feedback is trustworthy, and evolution is possible.
“Increasing determinism is the target. The pipeline is really just the amplifier that helps us to see how close we are to it.”
Every time you inject a clock instead of calling now(), every time you extract a pure function from a side-effecting method, every time you pin a dependency or make a deployment idempotent — you’re making your system more deterministic. And a more deterministic system is one that can evolve.
That’s the simplest way to make your architecture testable and reproducible. It works every time.